

AIの進化が続く中、特にLarge Language Model(LLM)の分野で目覚ましい進歩が見られます。OpenAIのChat GPTに端を発し、多くの企業や大学がLLM開発に力を入れています。2024年3月27日、新しいLLMが発表されました。本記事では、そのLLMであるDBRXをご紹介します。
- DBRXとは
DBRXはDatabricks社が開発したLLMで、総パラメーター数は132Bとトップレベルになっています。推論速度が速く、コーディングが得意なのが特徴です。
- Databricksによる性能調査
DatabricksがDBRXとほかの主要なLLMを様々な形で比較調査を行っているのでその結果を見てみましょう。
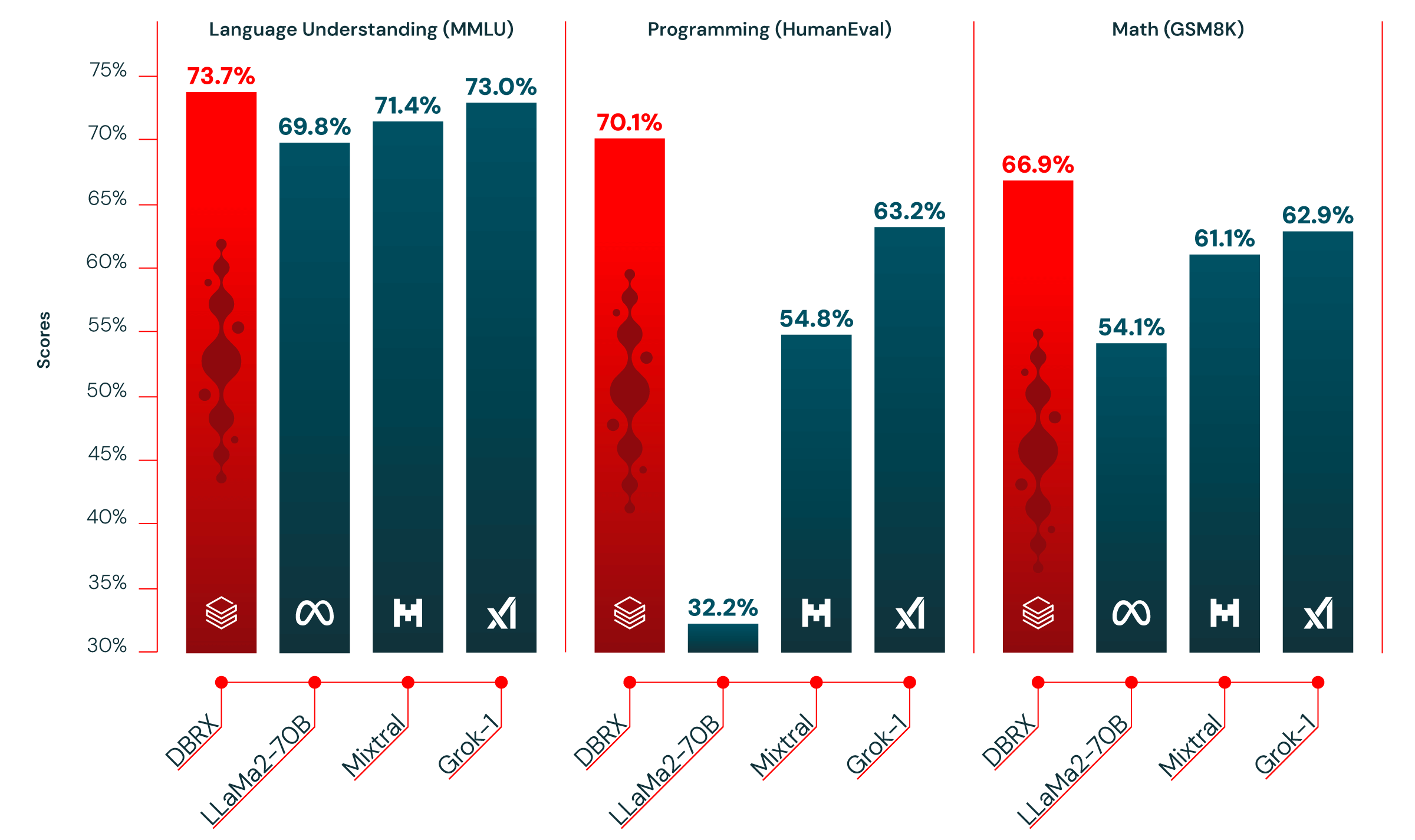
このグラフは言語理解、プログラミング、数学の理解力をそれぞれのベンチマークで評価したものです。比較するLLMはMeta社のLlama2-70B、Mistral AI社のMixtral、xAI社のGrak-1です。どれも新しい高性能のLLMですが、DBRXはすべての評価で最高値をとっています。
さらにChat GPTやClaude、Geminiなどのクローズドモデルとの比較でも、Databricksが調査したほぼすべてのベンチマークにおいてDBRXがGPT3.5を上回り、
いくつかのカテゴリでGemini1.0proにも引けを取らない性能を示しました。
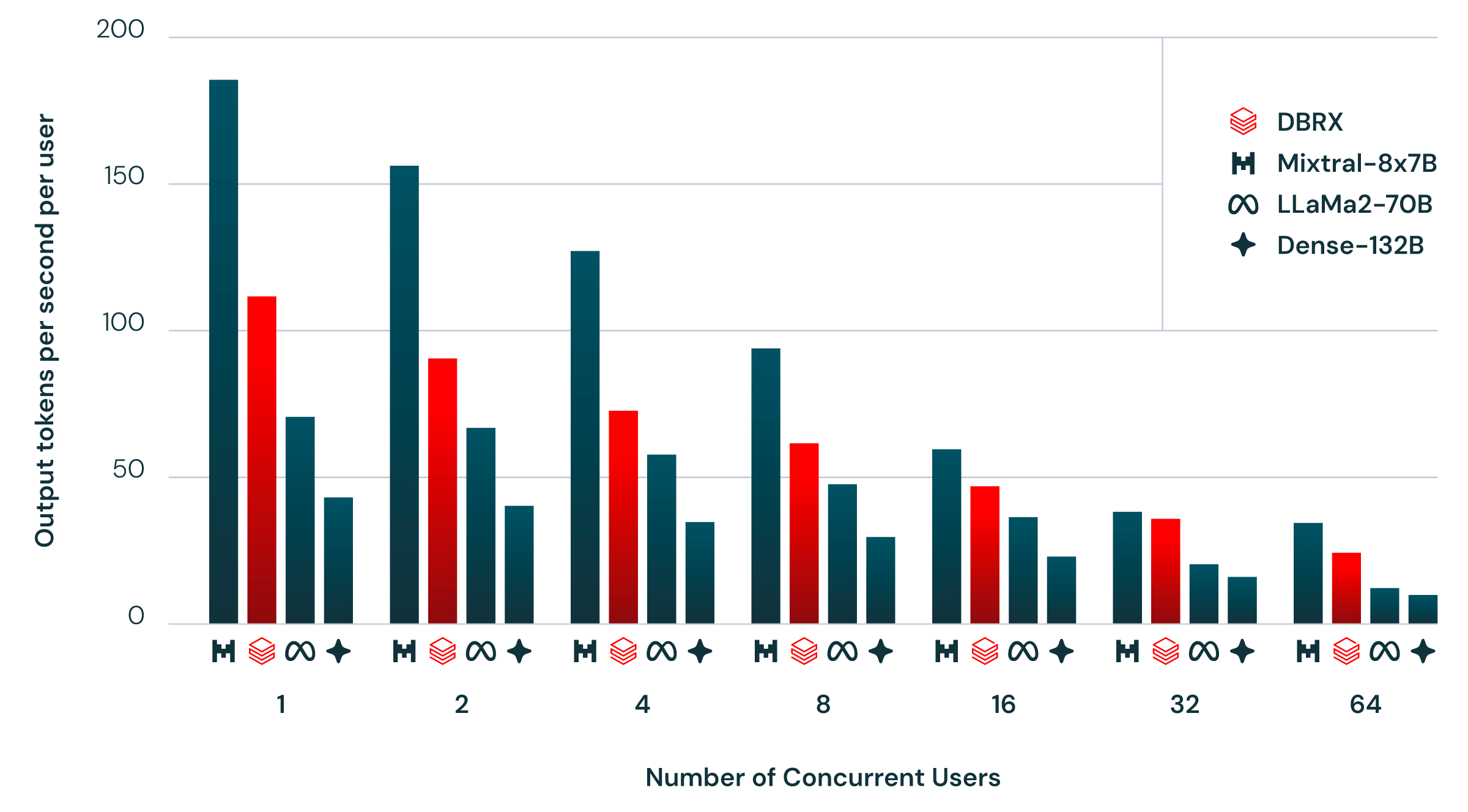
推論効率について説明します。上のグラフは、NVIDIA TensorRT-LLMを使った最適化サーバーでDBRXを実行した際の効率を示しています。これは、同時に複数のユーザーがアクセスする状況を再現しています。毎秒1人の新規ユーザーが追加され、各リクエストには約2000トークン、各レスポンスには256トークンが含まれます。
MoEモデルは、総パラメータ数の割に推論が高速です。DBRXも例外ではなく、132Bの非MoEモデルより2~3倍のスループットがあります。
一般的に、モデルが大きいほど質が高くなりますが、小さいモデルの方が推論効率は高くなります。MoEアーキテクチャを使用することで、このトレードオフが改善されます。例えば、DBRXはLLaMA2-70Bよりも高品質でありながら、推論スループットは最大2倍速いです。DBRXは8ビット量子化で最適化されたサービングプラットフォーム上で、毎秒最大150トークンの推論が可能です。
- 利用方法
Huggingface、またはGithubのいずれかのサイトにアクセスすると無料で利用できます。
DBRX Instruct – a Hugging Face Space by databricks